Natural Language Processing¶
Suggested Prerequisites¶
Overview¶
Basics¶
Word Tokenization¶
Word Tokenization also called as word segmentation is the process of dividing a string of written language into its component words. In English and many other languages using some form of Latin alphabet, space is a good approximation of a word divider.
However, we still can have problems if we only split by space to achieve the wanted results. Some English compound nouns are variably written and sometimes they contain a space. Mostly making use of a library to achieve the wanted results, is a good idea.
For example:¶
San Francisco is a beautiful city.
In the above sentence we can clearly see that if we consider San and Francisco as two different words then it totally changes the meaning of the word.
Sentence Tokenization¶
Sentence Tokenization also called as sentence segmentation is the process of dividing a string of written language into its component sentences. The idea here looks very simple. In English and some other languages, we can split apart the sentences wherever we see a punctuation mark. However, even in English, this problem is not trivial due to the use of full stop character for abbreviations. When processing plain text, tables of abbreviations that contain periods can help us to prevent incorrect assignment of sentence boundaries. In many cases, we make use of built-in libraries to do the job for us.
Sources:
https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Stemming and Text Lemmatization¶
For many grammatical reasons, documents can contain different forms of a word such as drive, drives, driving. Also, sometimes we have related words with a similar meaning, such as nation, national, nationality.
The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form.
Example:¶
Consults, Cousultant, Consultants, contsulting => Counsult
Plays, Played, Playing => Play
dog’s, dog, dogs => dog
In the above examples we can see that all different grammatical forms of a word were converted to their base words this is basically what stemming and lemmatization do.
Stemming and lemmatization are special cases of normalization. However, they are different from each other. The major difference between them is that Lemmatization provides more meaningful words whereas in stemming the derived words may need not necessarily be meaningful. Hence the time taken to perform stemming is less than the time taken to perform lemmatization. Stemming is also easier to perform and runs faster. Also, the reduced “accuracy” may not matter for some applications.
Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes.
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma.
Sources:
https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Stop Words¶
Stop words are words which are filtered out before or after processing of text. When applying machine learning to text, these words can add a lot of noise. That’s why we want to remove these irrelevant words.
Stop words usually refer to the most common words such as “and”, “the”, “a” in a language, but there is no single universal list of stopwords. The list of the stop words can change depending on your application.
Examples:¶
[‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘our’, ‘ours’, ‘ourselves’, ‘you’, “you’re”, “you’ve”, “you’ll”, “you’d”, ‘your’, ‘yours’, ‘yourself’, ‘yourselves’, ‘he’, ‘him’, ‘his’, ‘himself’, ‘she’, “she’s”, ‘her’, ‘hers’, ‘herself’, ‘it’, “it’s”, ‘its’, ‘itself’, ‘they’, ‘them’, ‘their’, ‘theirs’, ‘themselves’, ‘what’, ‘which’, ‘who’, ‘whom’, ‘this’, ‘that’, “that’ll”, ‘these’, ‘those’, ‘am’, ‘is’, ‘are’, ‘was’, ‘were’, ‘be’, ‘been’, ‘being’, ‘have’, ‘has’, ‘had’, ‘having’, ‘do’, ‘does’, ‘did’, ‘doing’, ‘a’, ‘an’, ‘the’, ‘and’, ‘but’, ‘if’, ‘or’, ‘because’, ‘as’, ‘until’, ‘while’, ‘of’, ‘at’, ‘by’, ‘for’, ‘with’, ‘about’, ‘against’, ‘between’, ‘into’, ‘through’, ‘during’, ‘before’, ‘after’, ‘above’, ‘below’, ‘to’, ‘from’]
Bag-of-Words¶
Machine learning algorithms cannot work with raw text directly, we need to convert the text into vectors of numbers. This is called feature extraction.
The bag-of-words model is a popular and simple feature extraction technique used when we work with text. It describes the occurrence of each word within a document.
To use this model, we need to:
Design a vocabulary of known words (also called tokens)
Choose a measure of the presence of known words.
Any information about the order or structure of words is discarded. That’s why it’s called a bag of words. This model is trying to understand whether a known word occurs in a document, but don’t know where is that word in the document.
The intuition is that similar documents have similar contents. Also, from a content, we can learn something about the meaning of the document.
Regex¶
A regular expression, regex, or regexp is a sequence of characters that define a search pattern. Let’s see some basics.
match any character except newline
\w - match word
\d - match digit
\s - match whitespace
\W - match not word
\D - match not digit
\S - match not whitespace
[abc] - match any of a, b, or c
[^abc] - not match a, b, or c
[a-g] - match a character between a & g
Regular expressions use the backslash character (‘') to indicate special forms or to allow special characters to be used without invoking their special meaning. This collides with Python’s usage of the same character for the same purpose in string literals; for example, to match a literal backslash, one might have to write ‘\\’ as the pattern string, because the regular expression must be \, and each backslash must be expressed as \ inside a regular Python string literal.
We can use regex to apply additional filtering to our text. For example, we can remove all the non-words characters. In many cases, we don’t need the punctuation marks and it’s easy to remove them with regex.
TF-IDF¶
One problem with scoring word frequency is that the most frequent words in the document start to have the highest scores. These frequent words may not contain as much “informational gain” to the model compared with some rarer and domain-specific words. One approach to fix that problem is to penalize words that are frequent across all the documents. This approach is called TF-IDF.
TF-IDF, short for term frequency-inverse document frequency is a statistical measure used to evaluate the importance of a word to a document in a collection or corpus.
The TF-IDF scoring value increases proportionally to the number of times a word appears in the document, but it is offset by the number of documents in the corpus that contain the word.
Term Frequency (TF): a scoring of the frequency of the word in the current document.
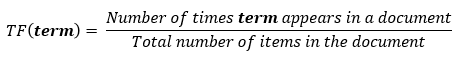
Inverse Term Frequency (ITF): a scoring of how rare the word is across documents.
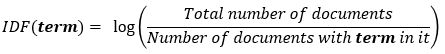
Finally, we can use the previous formulas to calculate the TF-IDF score for a given term like this: